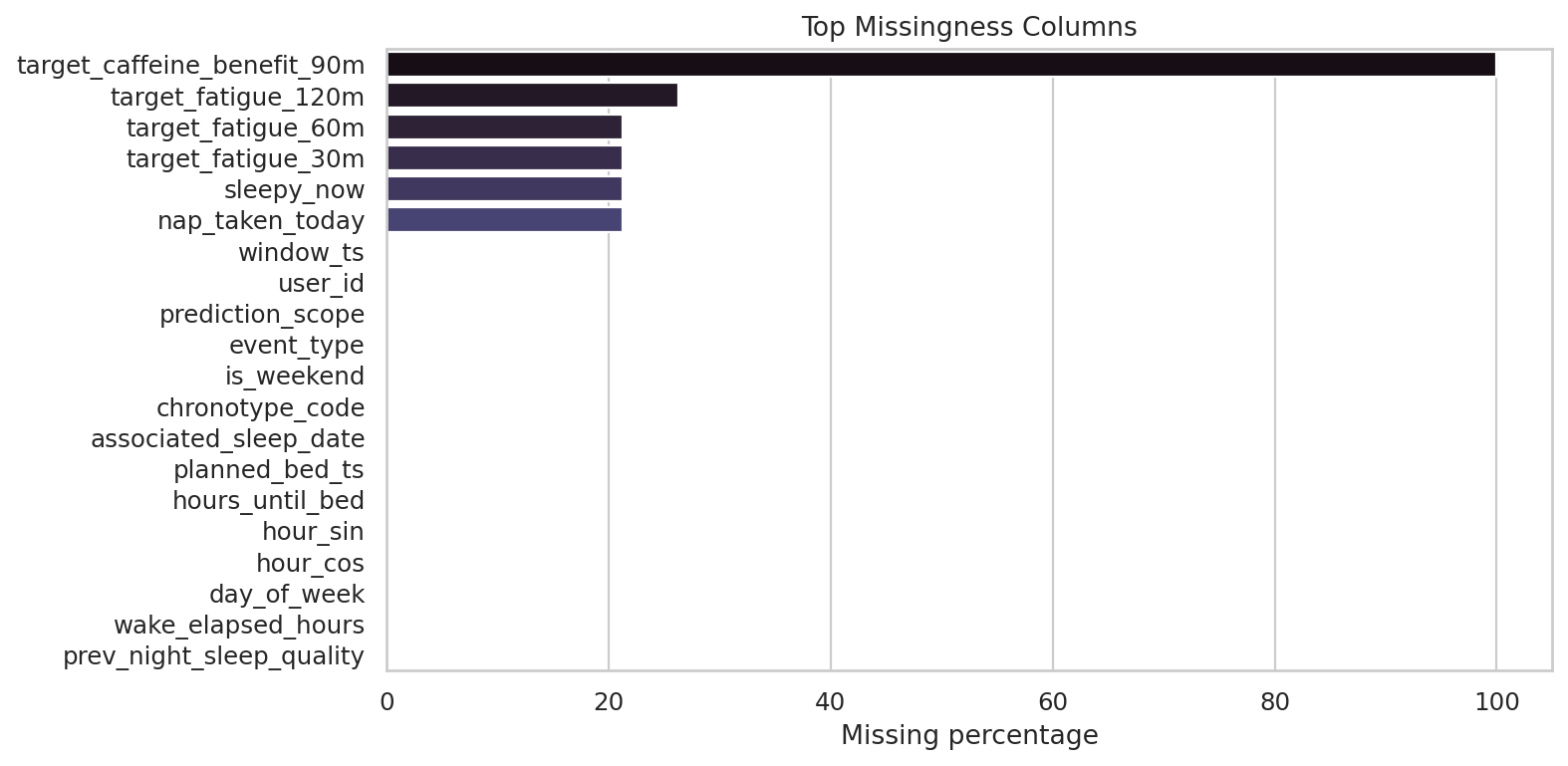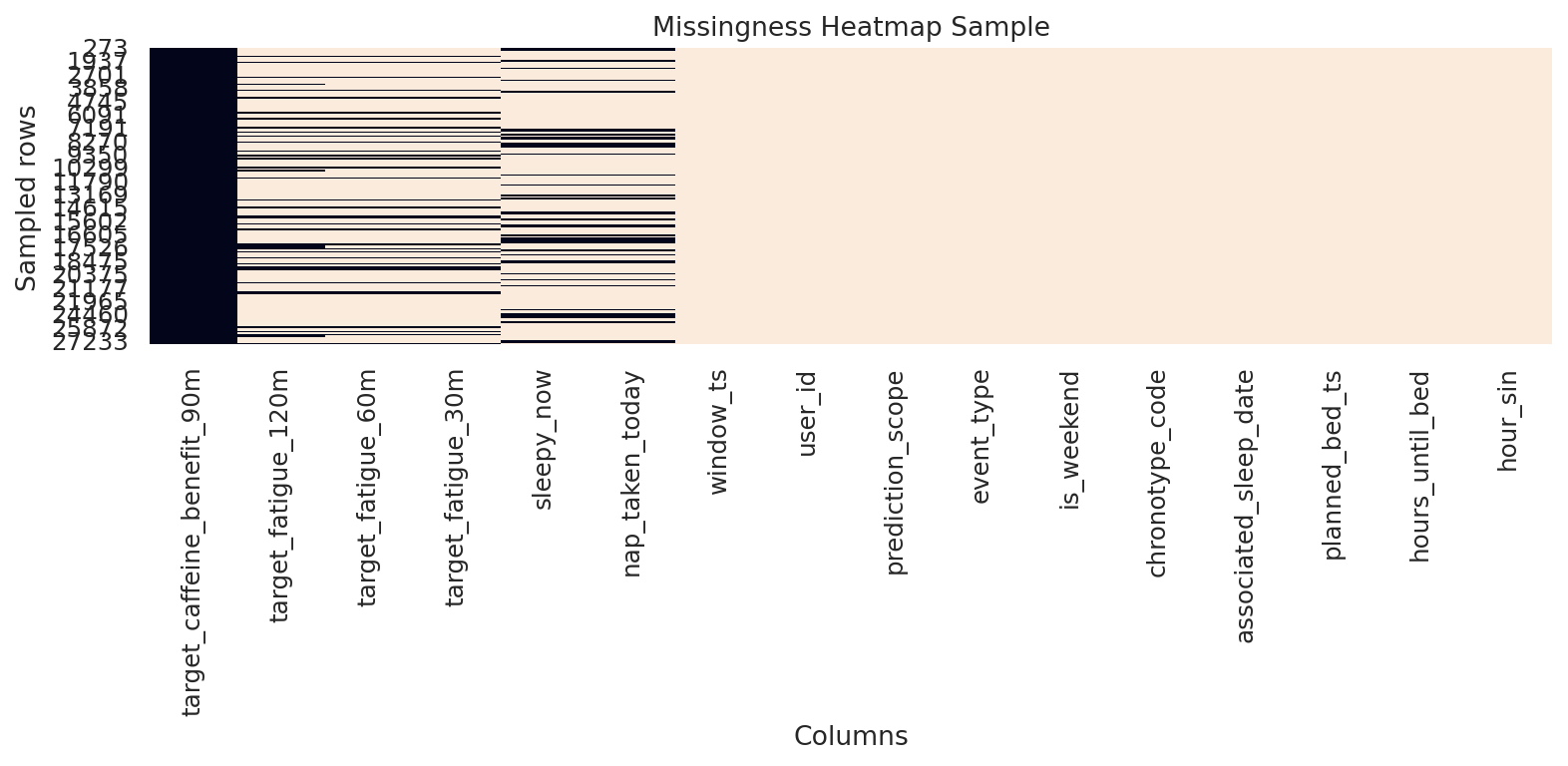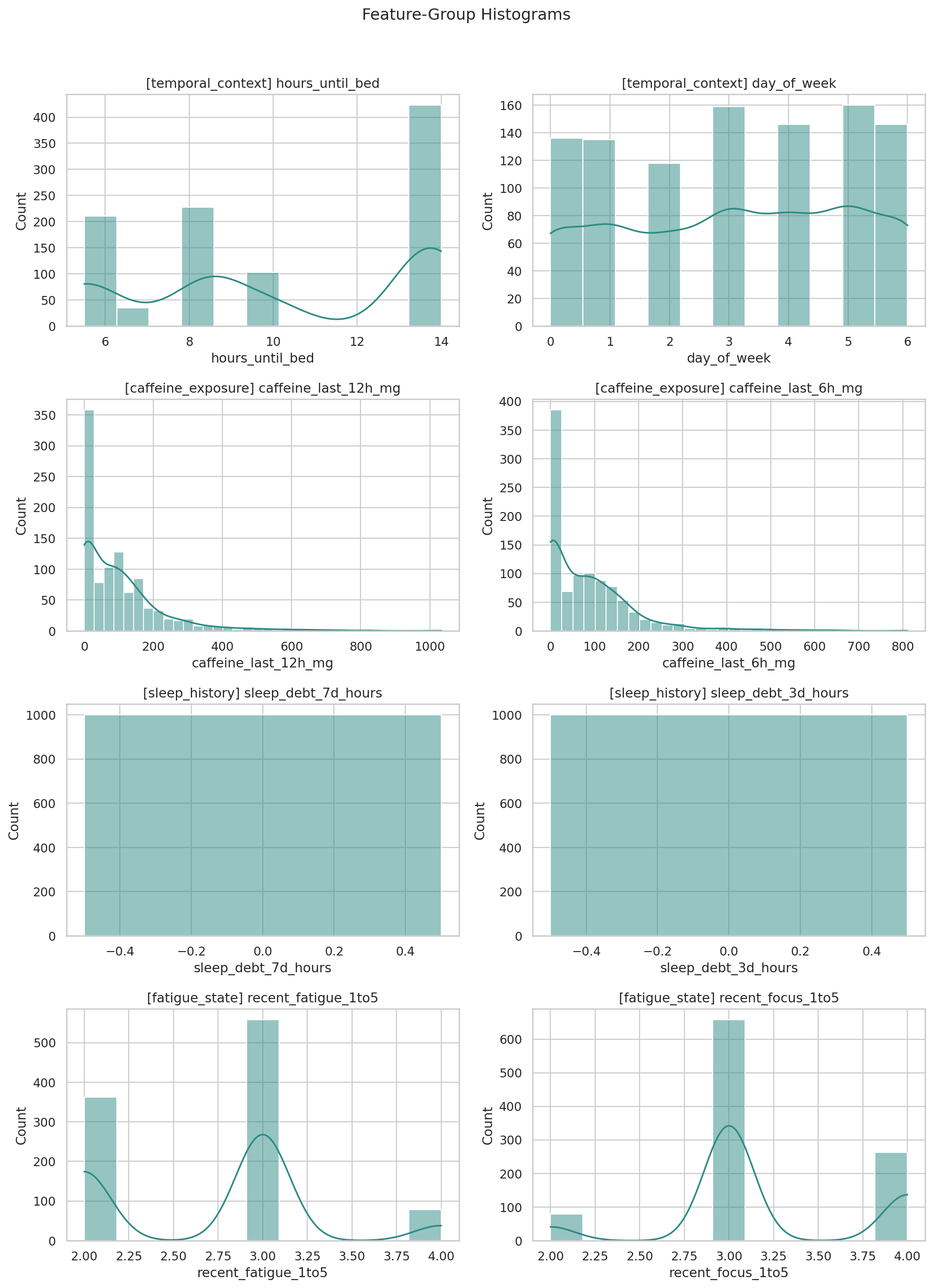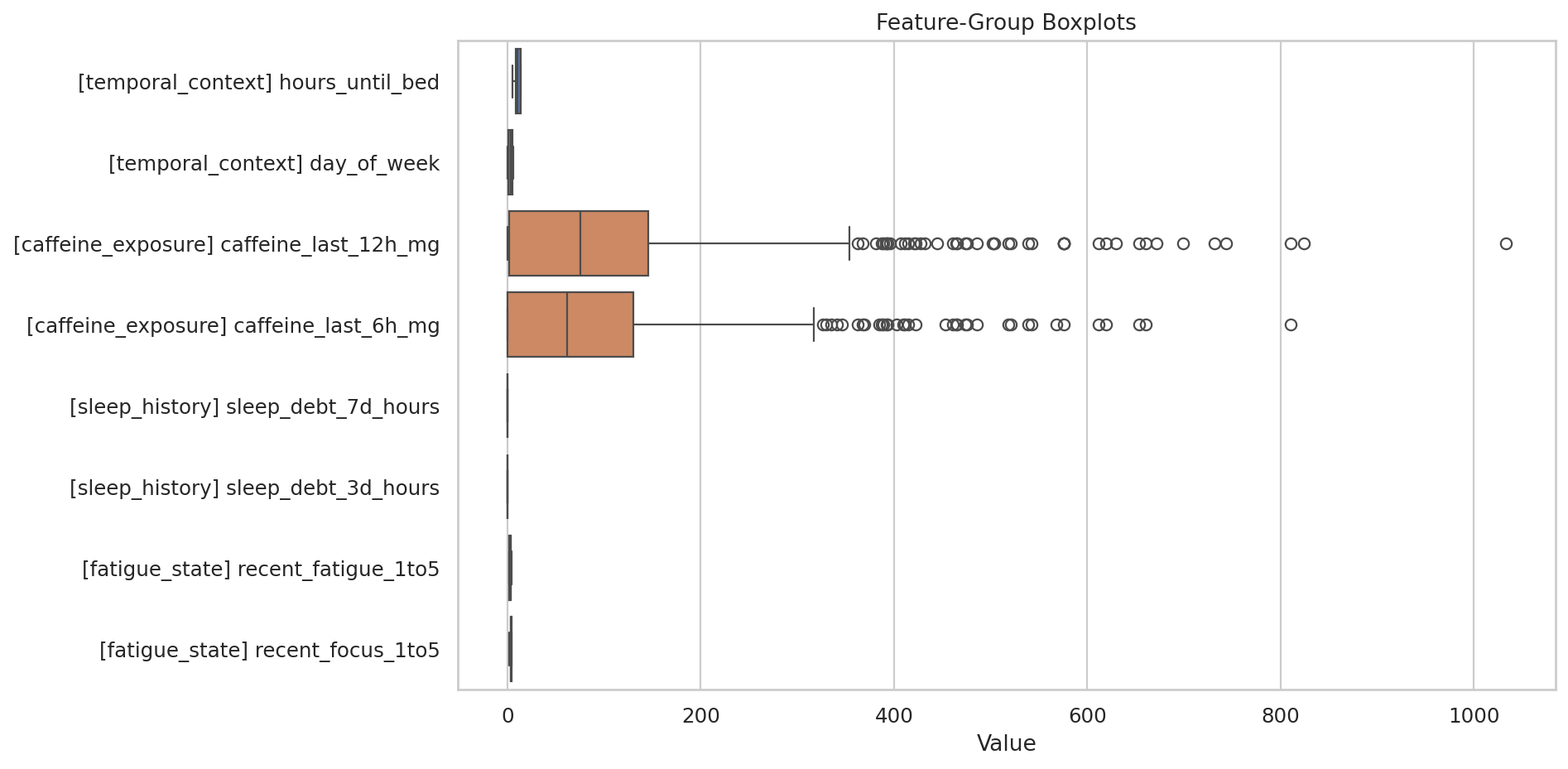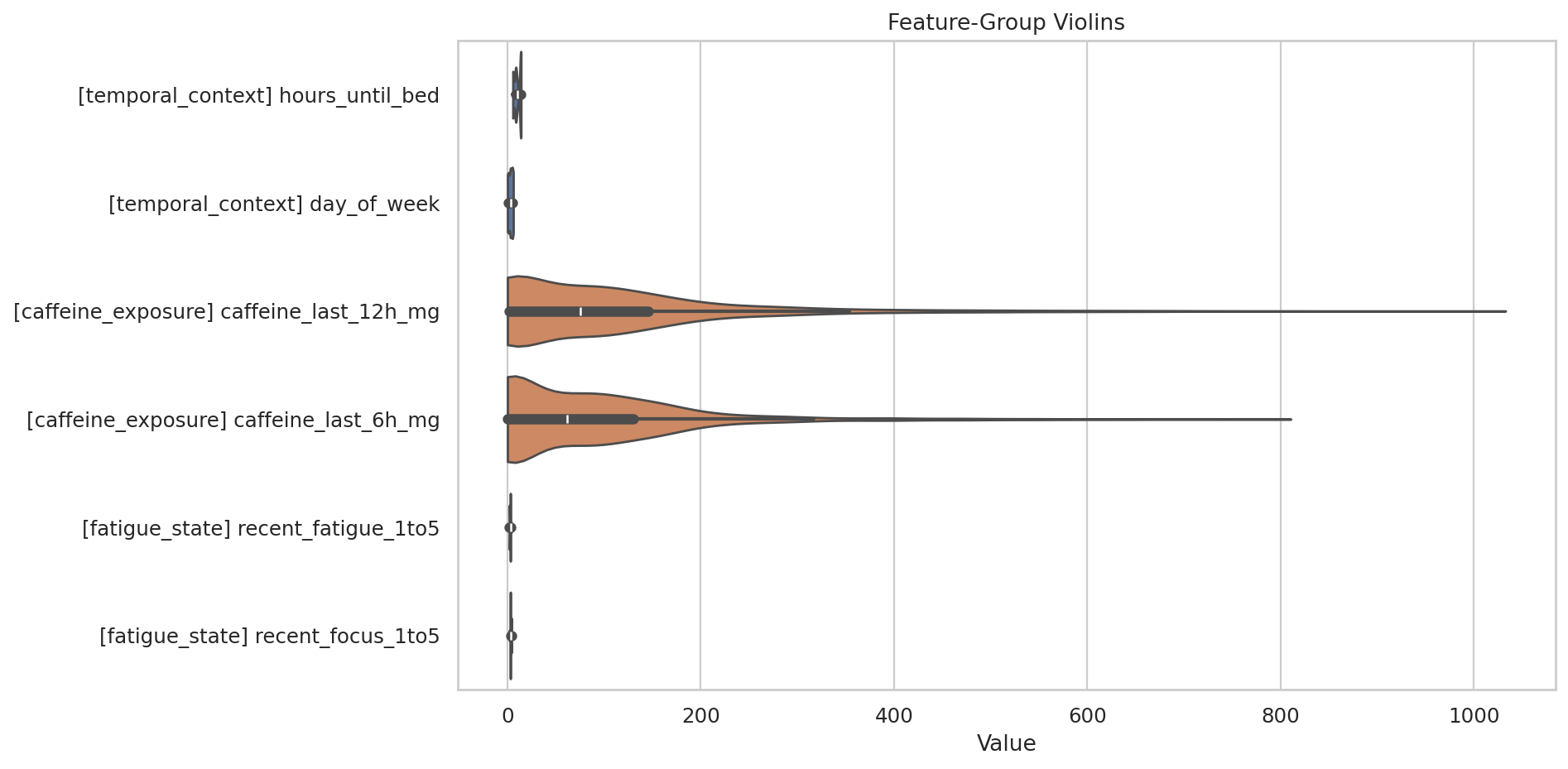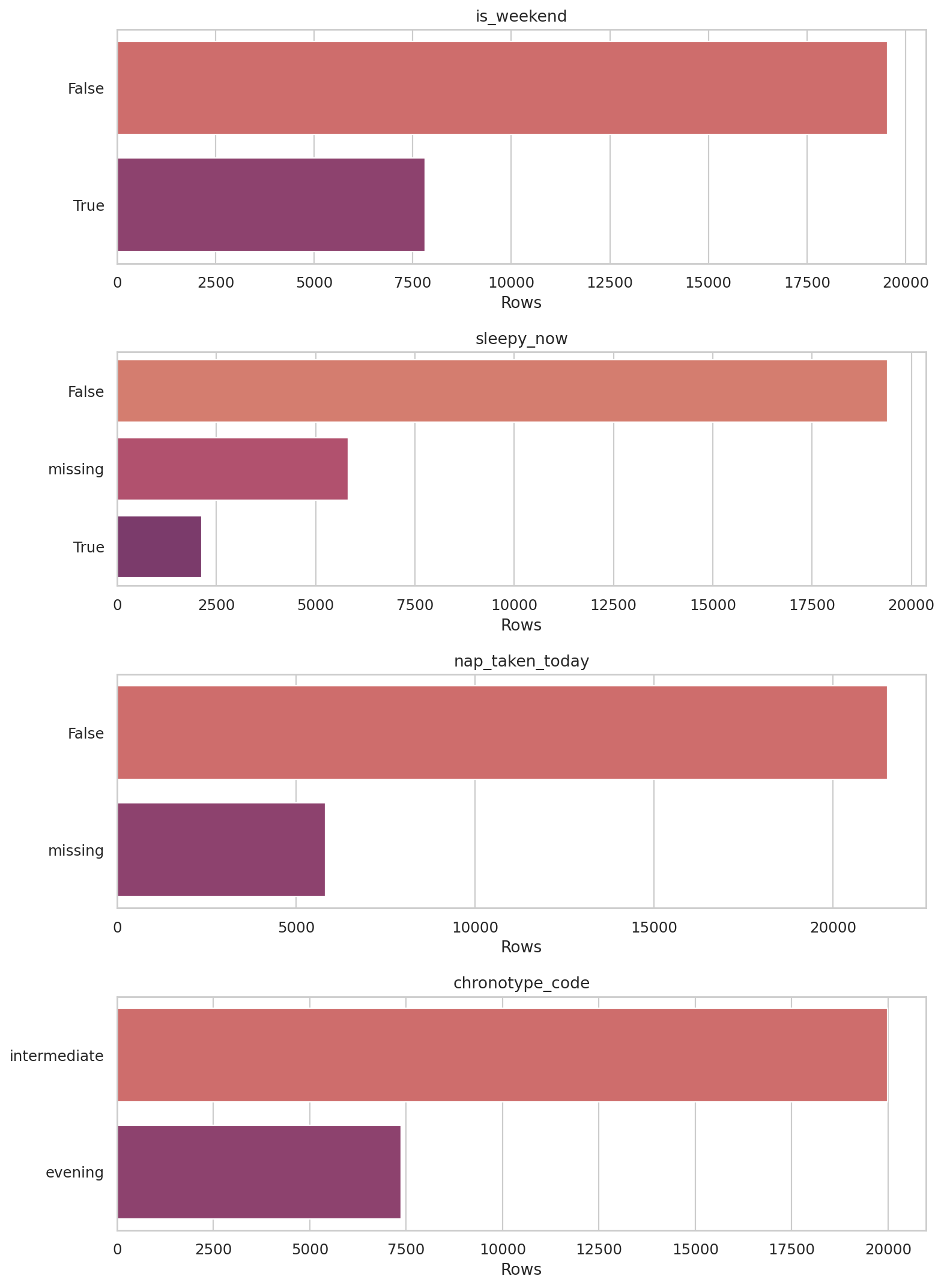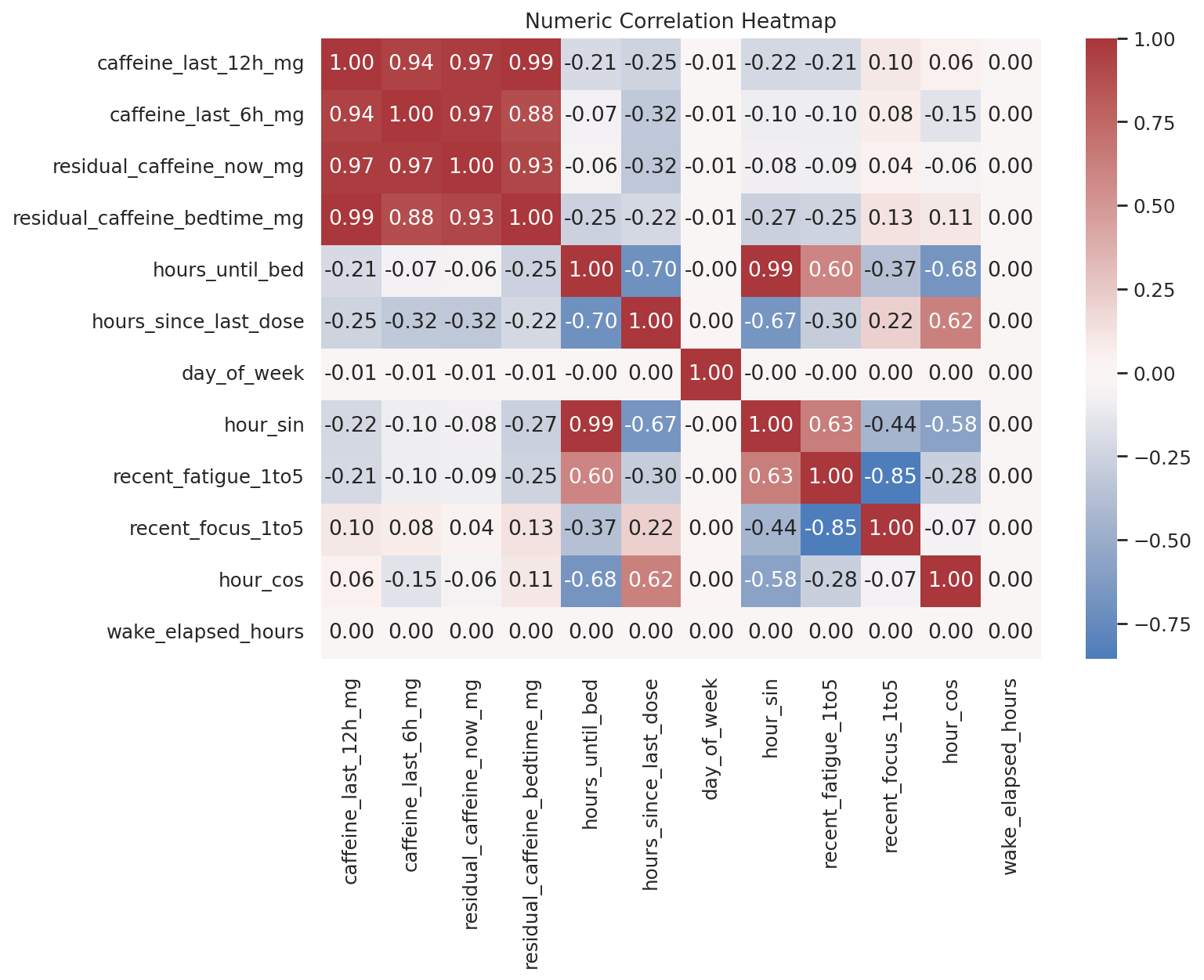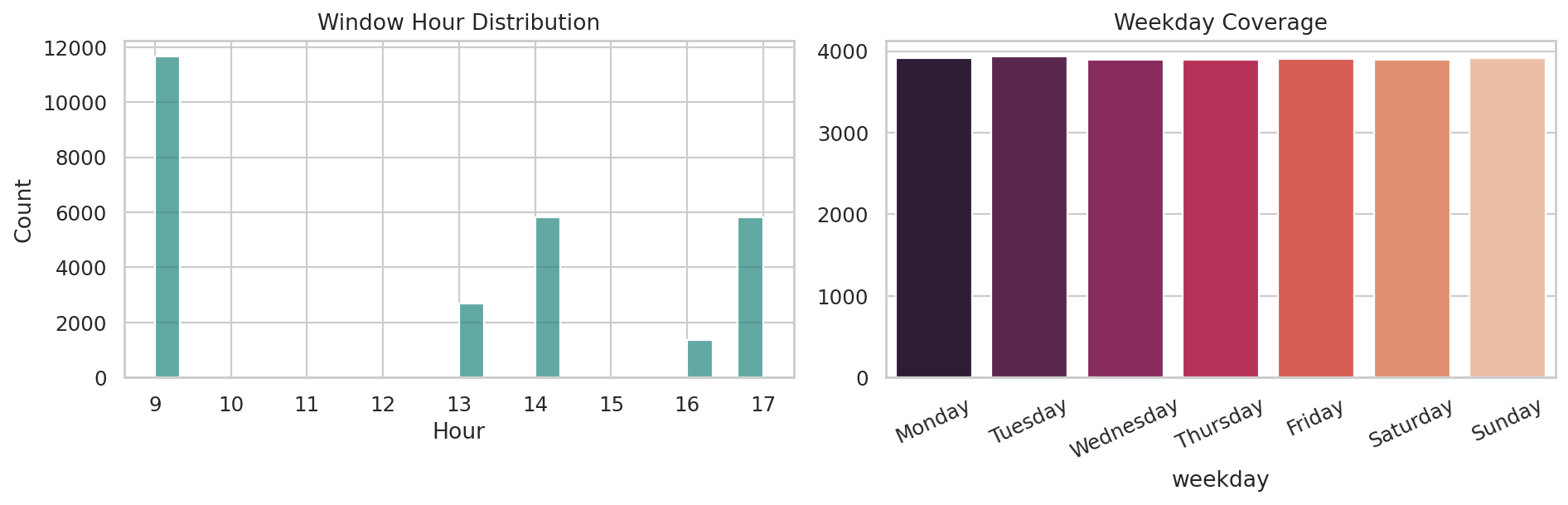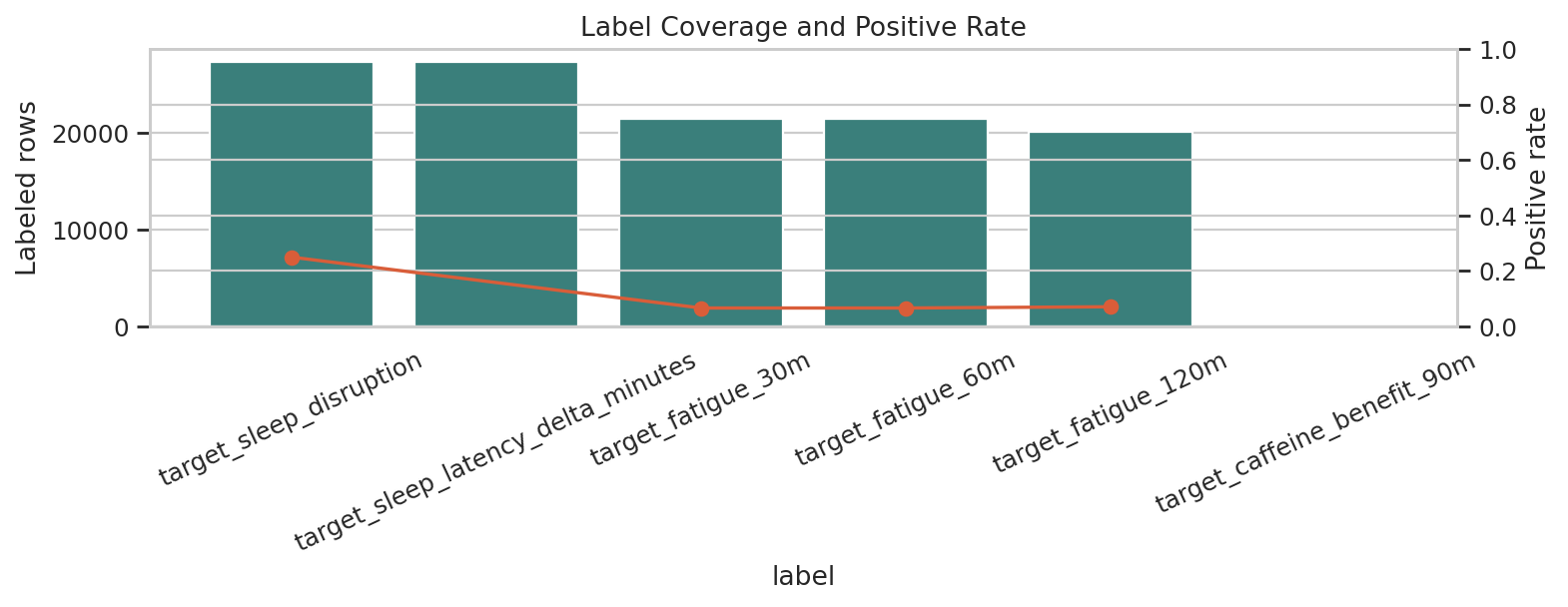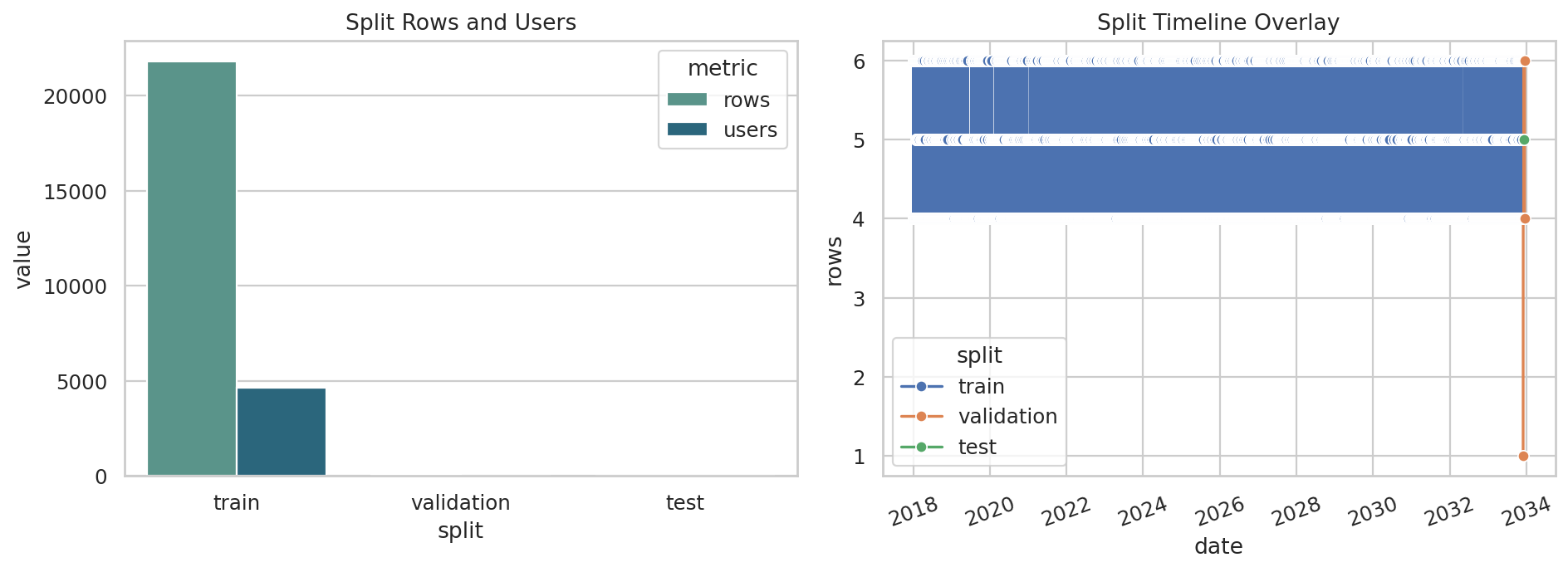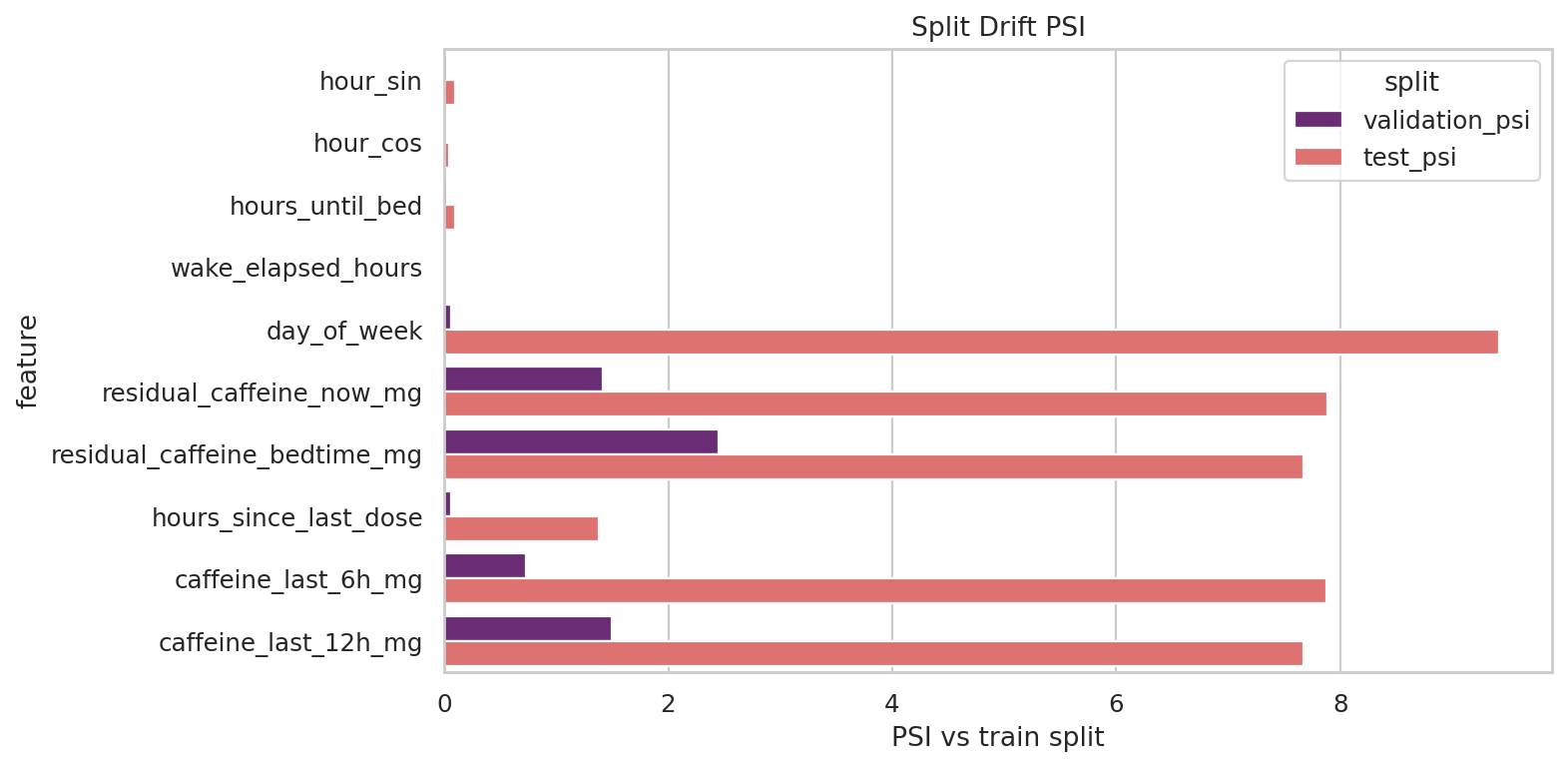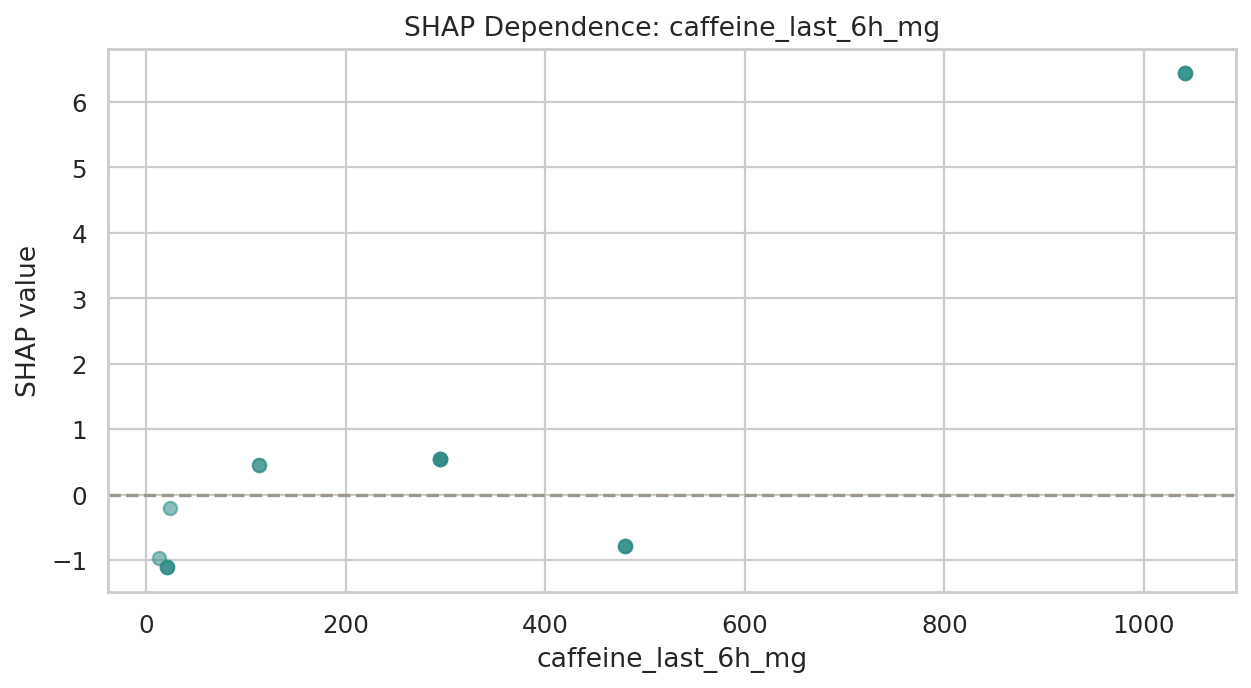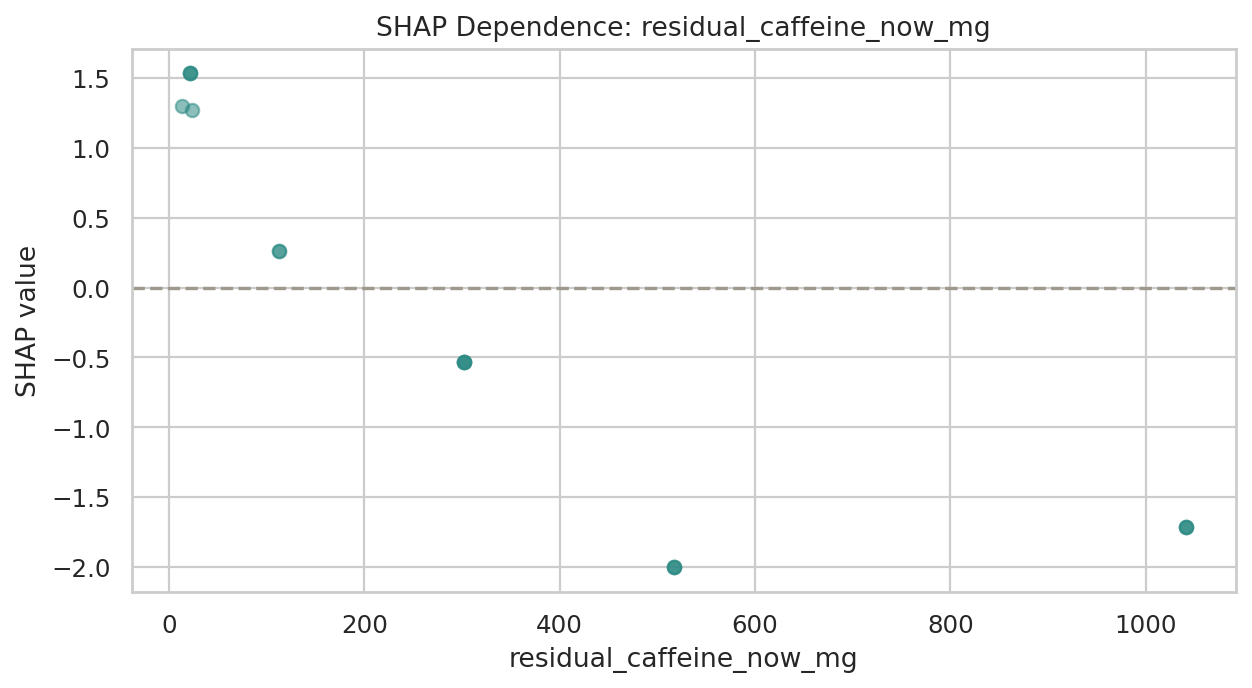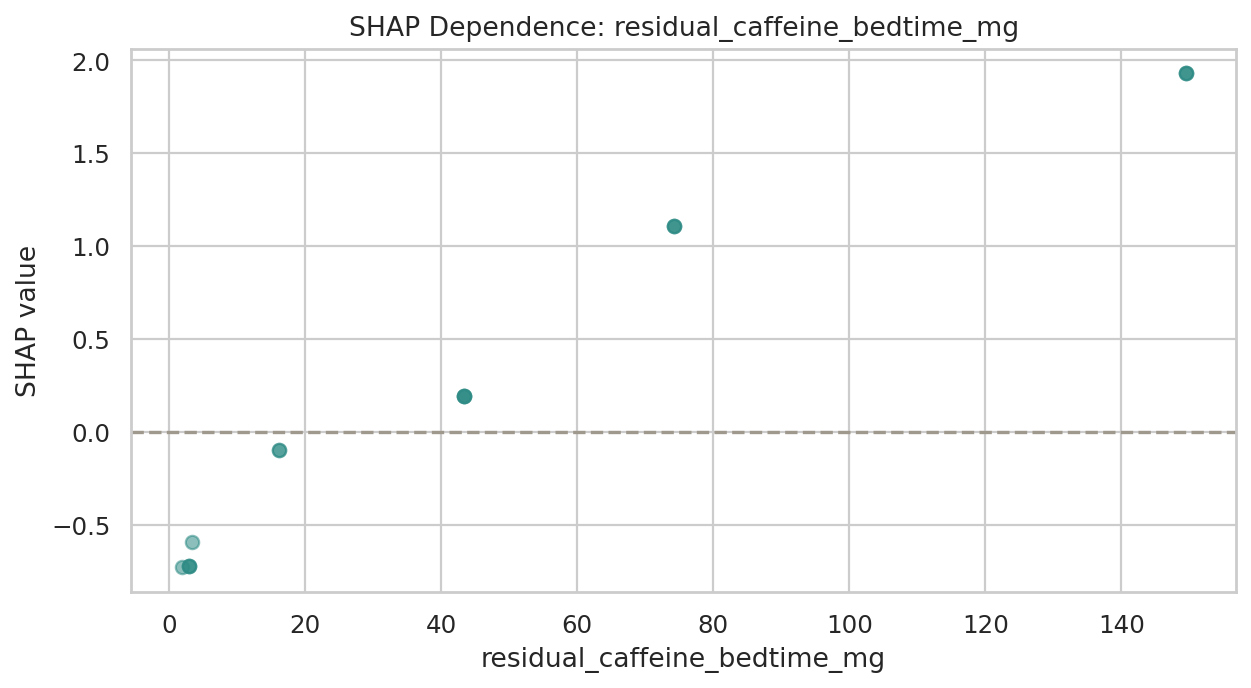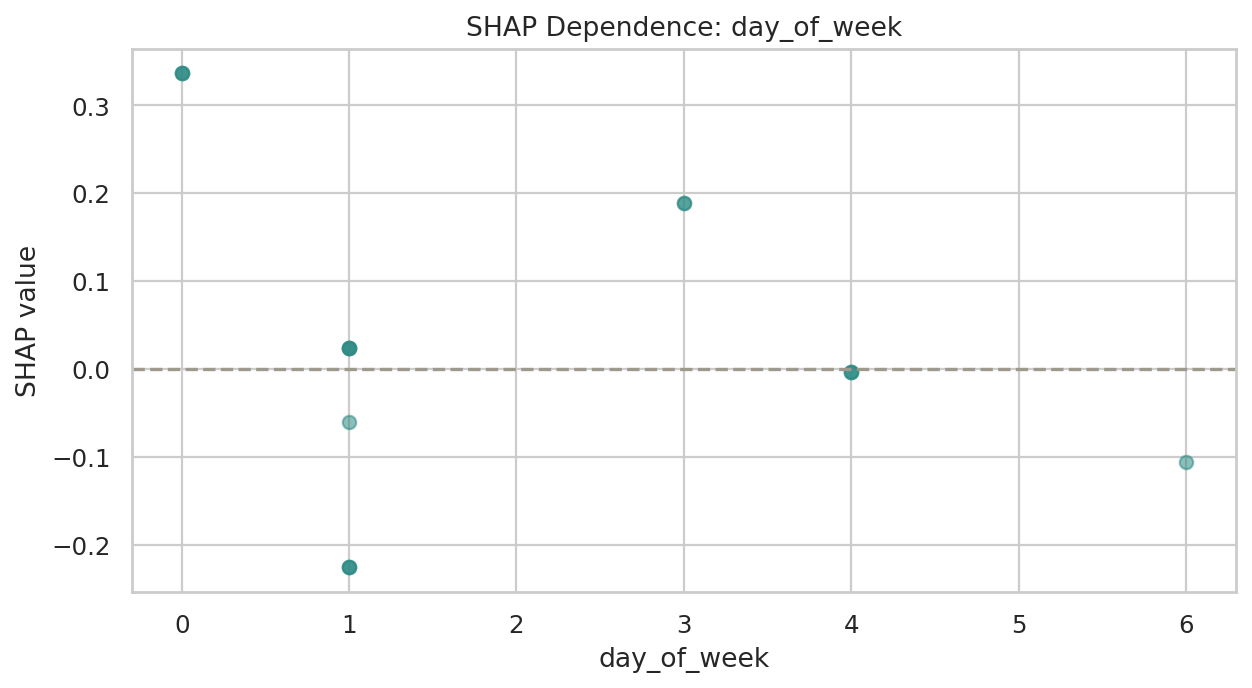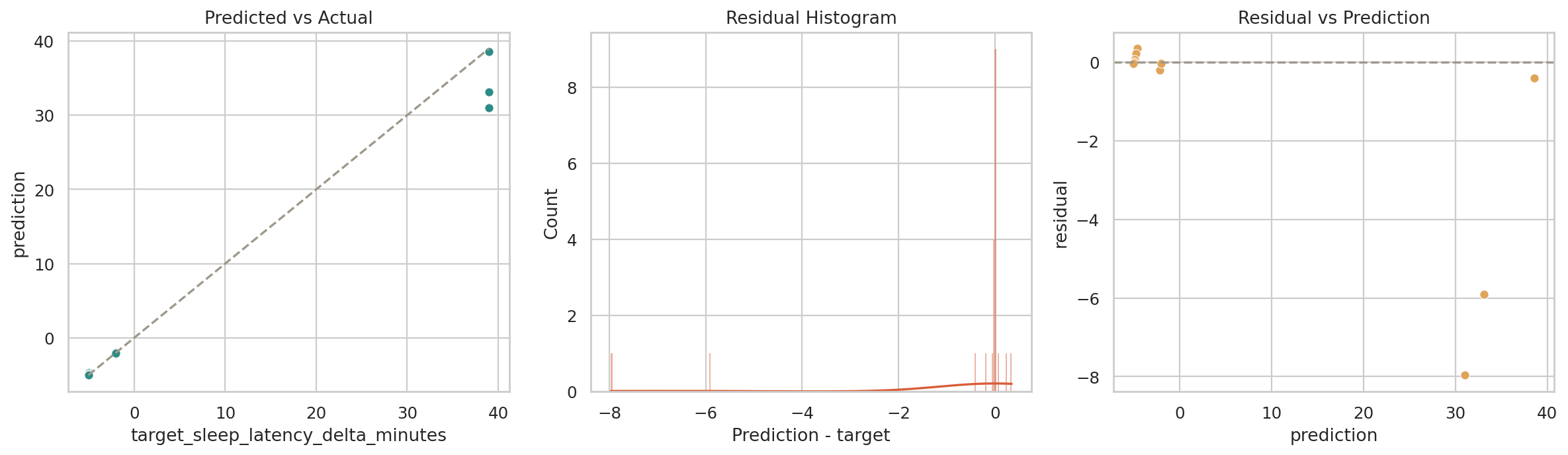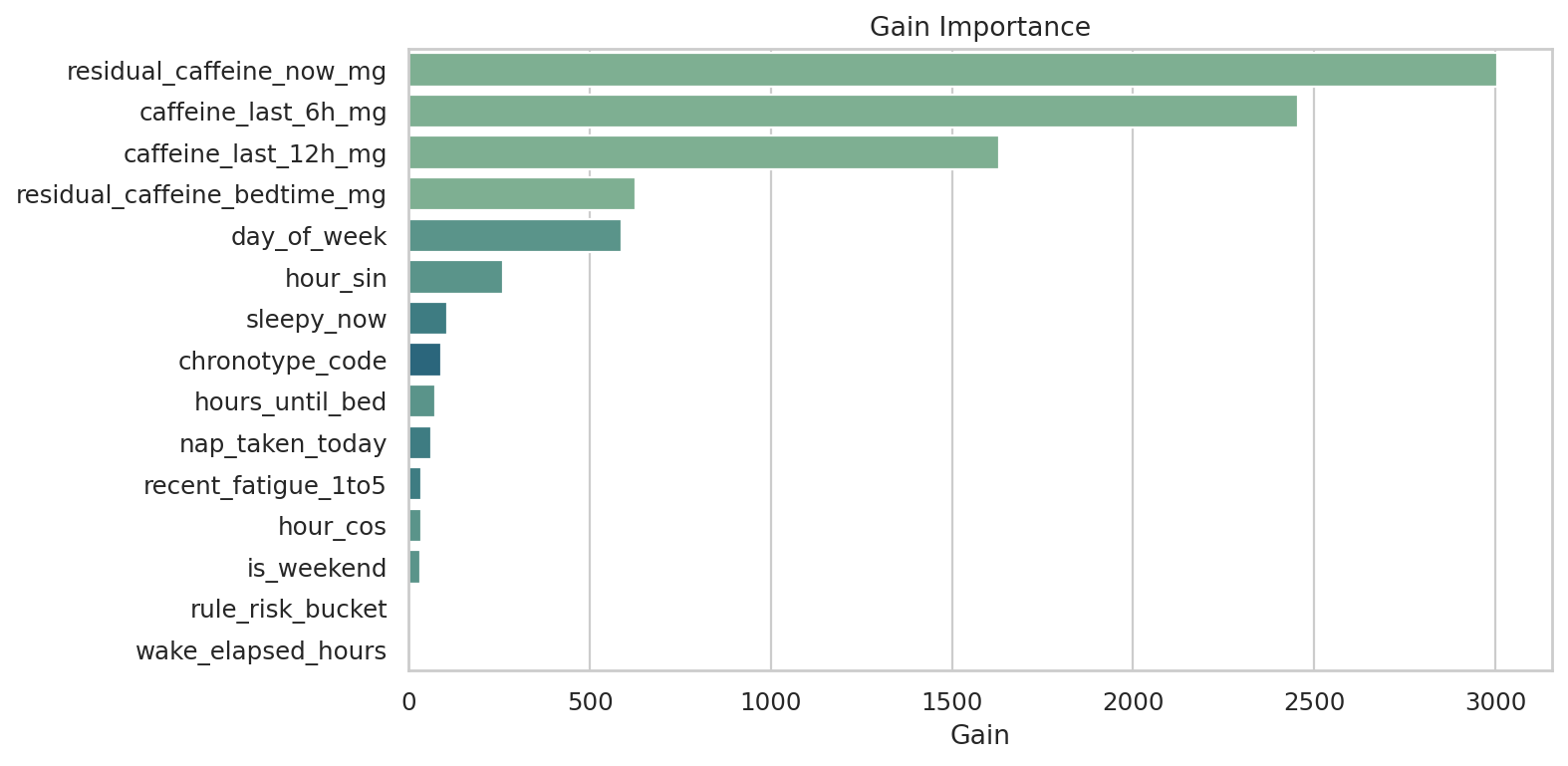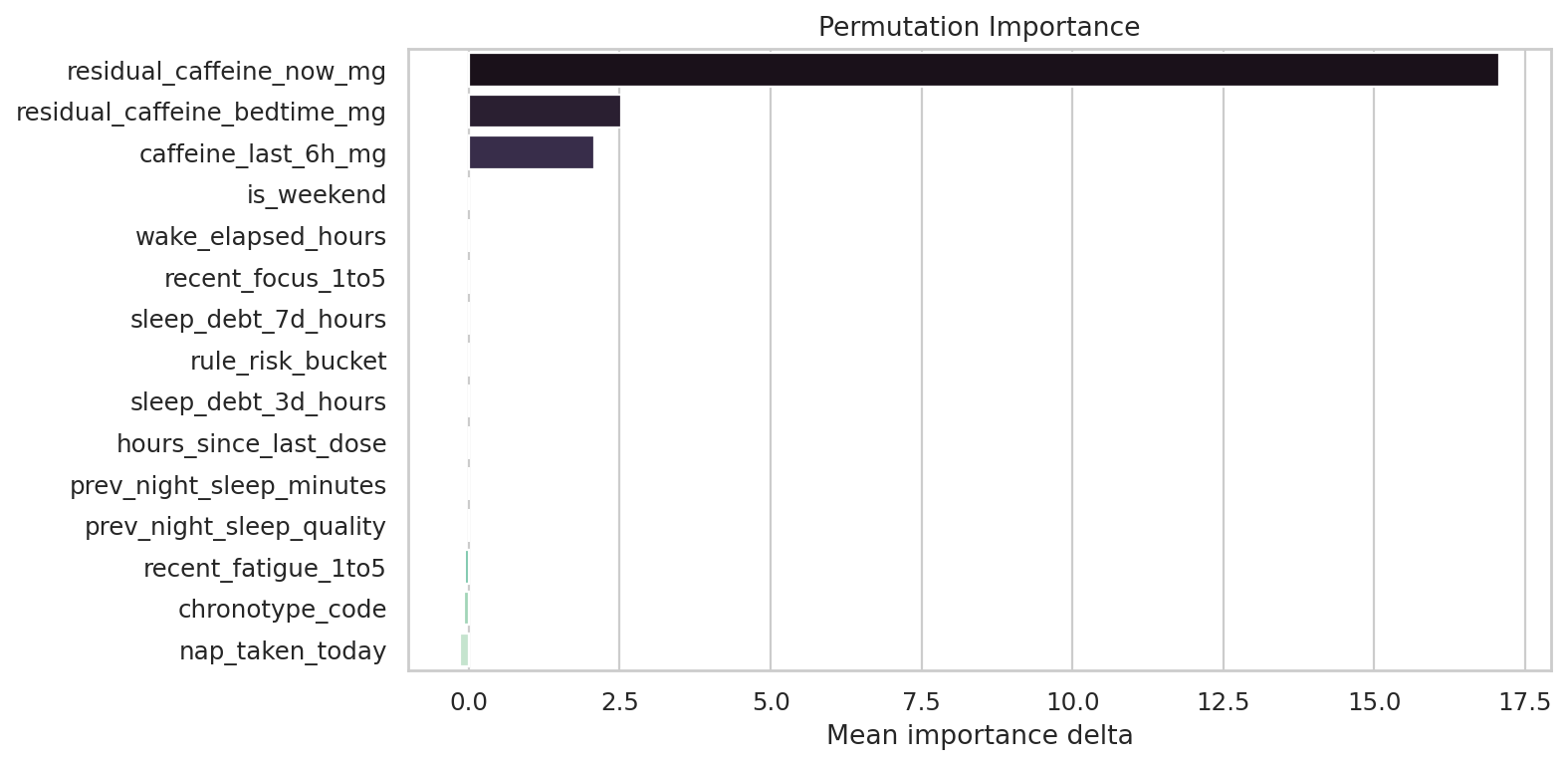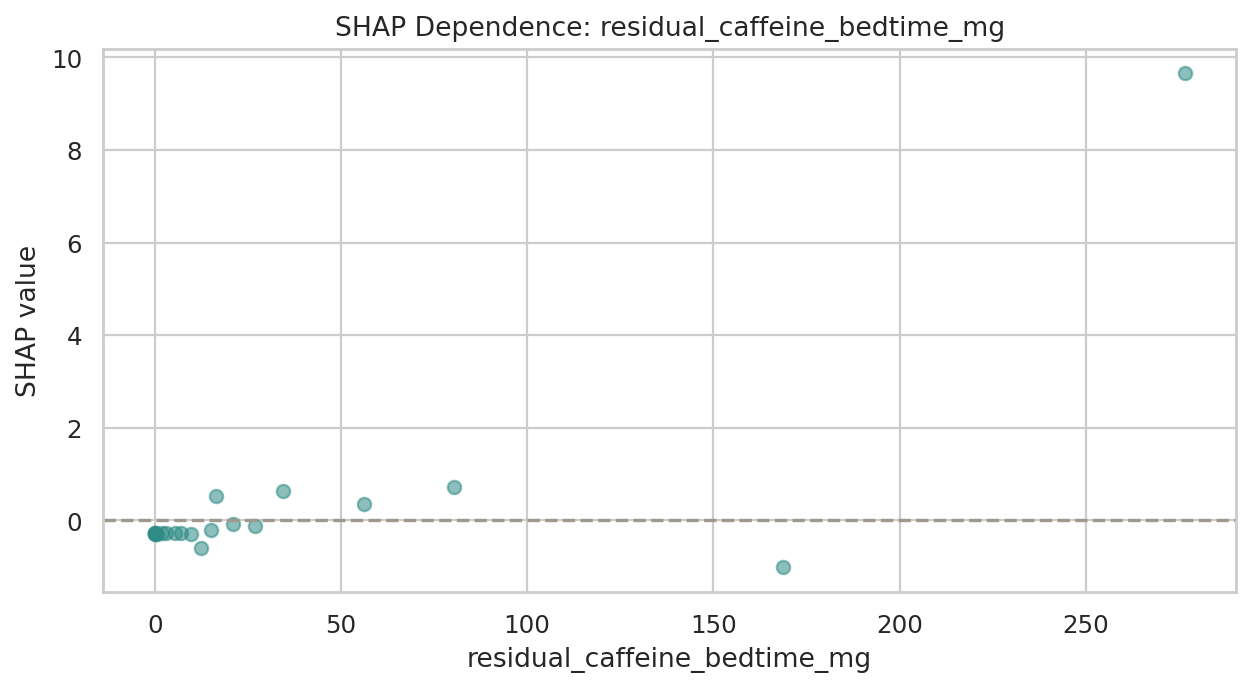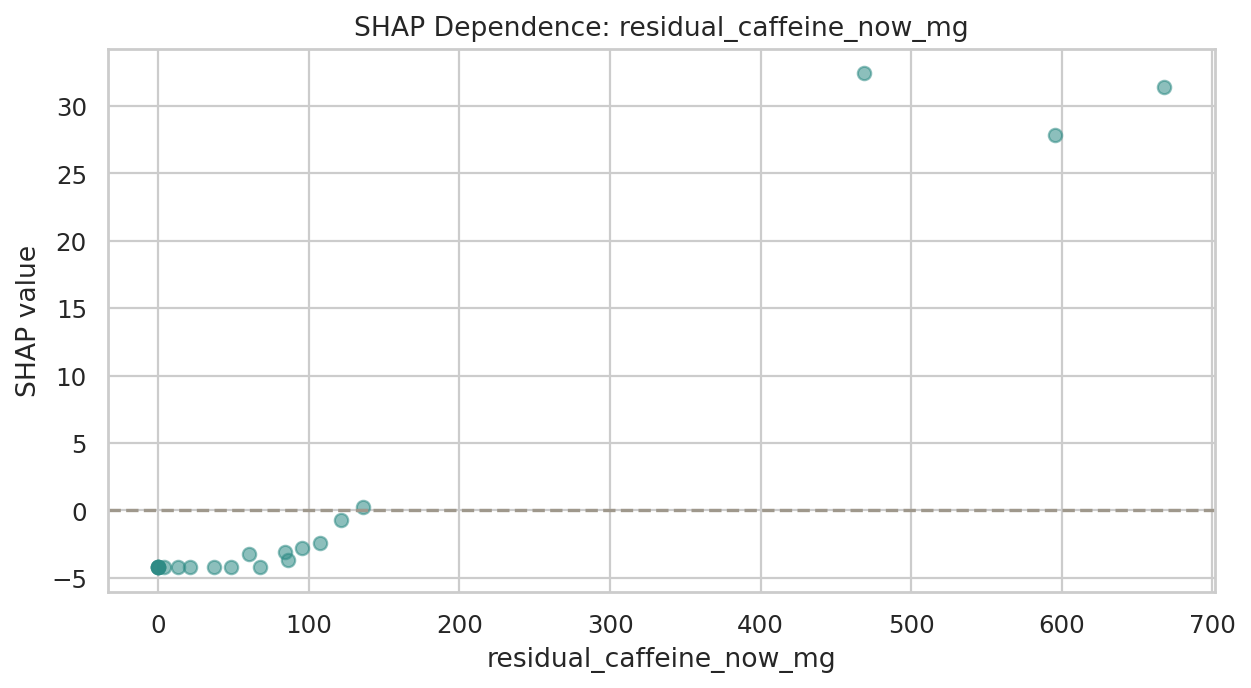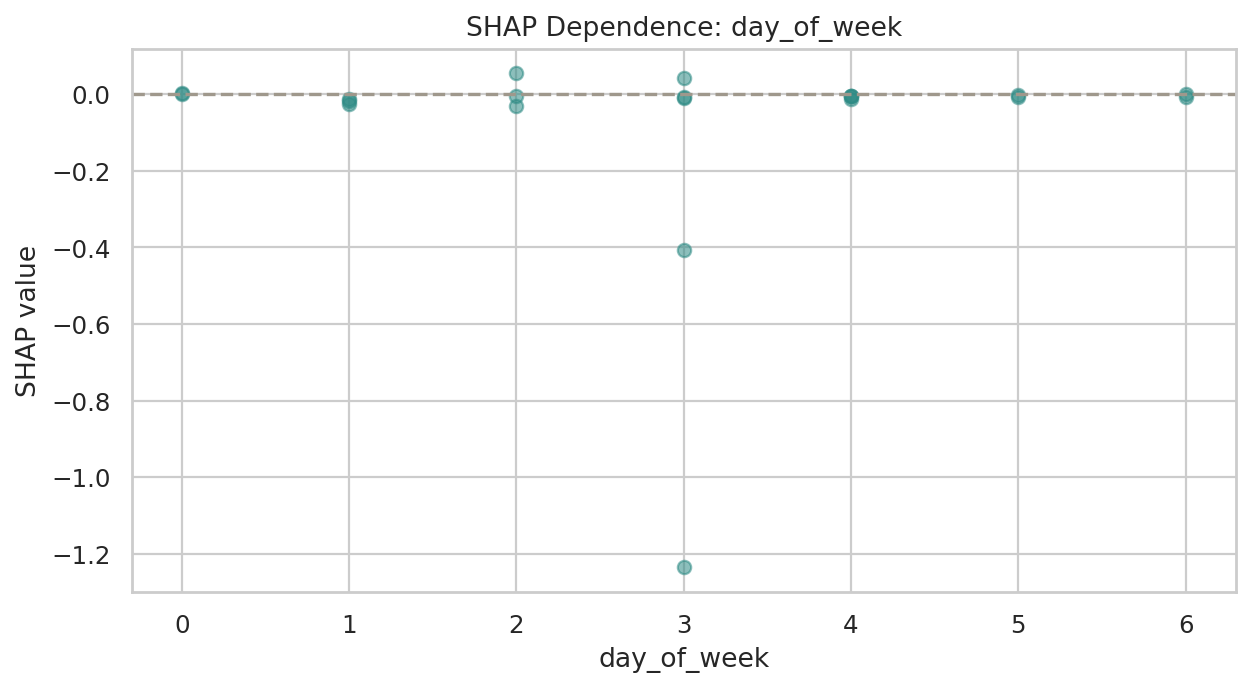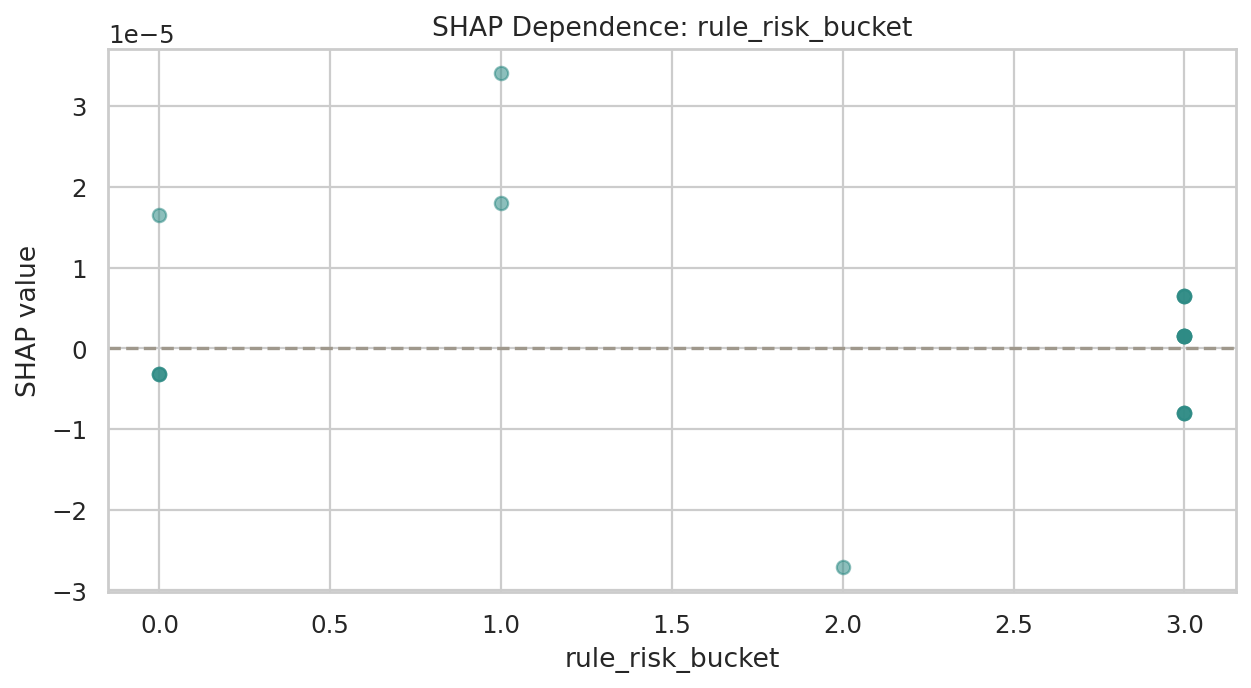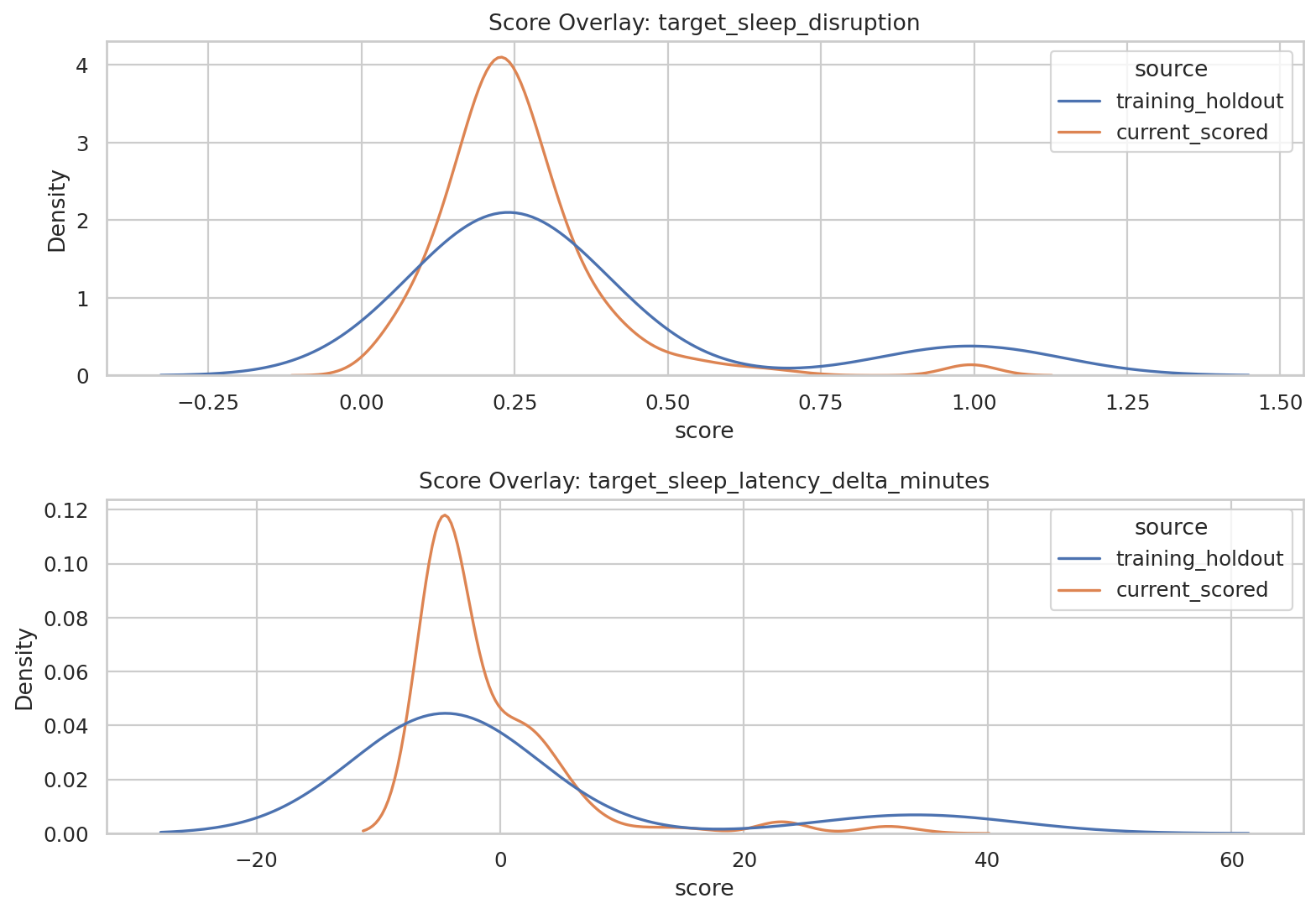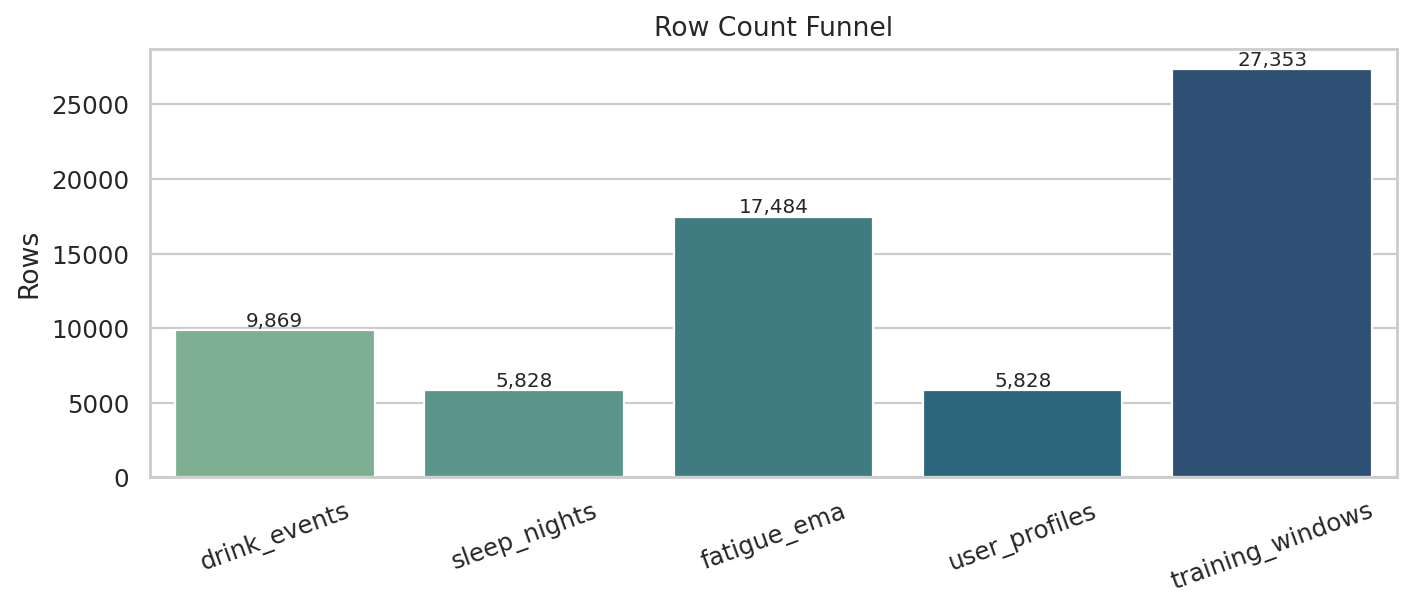
데이터 단계별 행 수
Row Count Funnel이 그래프가 답하는 질문
원본 입력부터 학습 윈도우, 점수 산출 데이터까지 각 단계에서 데이터 양이 어떻게 바뀌는지 보여줍니다.
읽는 법
막대가 높을수록 해당 단계에 들어 있는 행 수가 많다는 뜻입니다.
먼저 볼 포인트
특정 단계에서 행 수가 갑자기 크게 줄어드는 지점을 먼저 보세요.
주의할 점
행 수가 줄었다고 항상 문제는 아닙니다. 중복 제거나 라벨 조건 때문에 자연스럽게 줄 수 있습니다.